Léxico Multifuncional Computorizado do Português Contemporâneo
Financiamento:
JNICT / FCT – Programa PRAXIS XXI (Contrato 2/2.1/CSH/759/95)
Estado do Projecto:
Concluído
Resumo:
Na sequência deste projecto, o português europeu conta agora com um Léxico de Frequências de 26.443 vocábulos, e das 140.315 formas lematizadas desses vocábulos, extraído de um corpus muito significativo (16.210.438 palavras1) do português contemporâneo; as entradas lexicais que o constituem atingiram, no corpus, frequências iguais ou superiores a 6. Cada entrada lexical (vocábulo) é seguida de informação gramatical (categoria morfossintáctica) e de informação quantitativa (nível de ocorrência no corpus). As mesmas informações são dadas para todas as formas lexicais (formas flexionadas e alguns compostos) de cada vocábulo. As indexações do léxico são feitas por ordem alfabética e por ordem de frequências decrescentes.
Este recurso está disponível gratuitamente no Catálogo ELRA com o International Standard Language Resource Number (ISLRN) 489-956-642-755-8.
Mais informações em http://www.islrn.org/.
DESCRIÇÃO DO PROJECTO
O corpus
Para a realização do projecto, o CLUL desenhou e extraiu do seu corpus monitor Corpus de Referência do Português Contemporâneo (CRPC)2 um corpus de 16.210.438 palavras - o CORLEX, que contém um subcorpus de língua escrita (15.354.243 palavras) e um subcorpus de língua falada (856.195 palavras).
Do CORLEX fazem parte textos orais e escritos que cobrem uma grande variedade de tipos de linguagem, sendo a diversidade de géneros e de matérias uma dominante deste corpus. A maior proporção do corpus jornalístico (56% do corpus escrito e 53% do corpus total) teve em vista o predomínio, no corpus, de uma linguagem comum e a cobertura de uma enorme diversidade de temas.
Constituição do corpus escrito (15.354.243 palavras)
Uma parte deste corpus é constituída por materiais cedidos ao CLUL pela editorial VERBO, membro da parceria deste Projecto.

As recolhas foram feitas em diversas Fontes, sendo o corpus constituído por amostragens dos títulos seleccionados.
Fontes do subcorpus jornalístico
Jornais
Nº de títulos de jornaisDatasNº de exemplaresNº de artigos
31997 e 199810513.085
Revistas
Nº de títulos de jornaisDatasNº de exemplaresNº de artigos
31992 a 199710513.085
Fontes do subcorpus literário
(Romances, Novelas, Contos, Poesia, Memórias e Teatro de autores portugueses)
Nº de AutoresNº de TítulosDatas
135186séc. XIX (2ª metade): 11 autores; 14 títulos
séc. XX: 124 autores; 172 títulos
Fontes do subcorpus Científico, Técnico e Didáctico3
Nº de Autores4Nº de TítulosDatas
91
livro científico e técnico - 68
livro didáctico - 2393
livro científico e técnico - 68
livro didáctico - 251980 - 1993
Fontes do subcorpus "Miscelânea"
Tipo de documentoNº de textos/artigosDatas
Jornais e revistas especializados3471900 - 1997
Outros documentos30
Constituição do corpus oral (856.195 palavras)
O corpus oral é constituído pela transcrição ortográfica do registo magnético de conversas informais e de produções mais formais (conferências, entrevistas na rádio e na televisão, etc.).
Tipo de discursoNº de palavrasNº de textosDatas
espontâneo752.3941409Décadas de 1970 e 1990
formal103.801150Década de 1980
O Léxico
Informação quantitativa
O INESC realizou cálculos probabilísticos para determinação das frequências de ocorrência no CORLEX, tomando como base os dados obtidos para o subcorpus PAROLE desambiguado.
A partir destes cálculos e das desambiguações manuais efectuadas no CLUL, obtiveram-se os dados quantitativos relativos aos lemas considerados no Léxico, ou seja, aqueles cuja Frequência é igual ou ultrapassa o limiar estabelecido (F6).
Assim, junto de cada entrada e de cada forma dessa entrada é apresentada uma aproximação do seu número de ocorrências. Uma vez que o intervalo de variação de ocorrência é muito grande, quer para as entradas, quer para as formas, utilizou-se uma escala logarítmica, a partir do logaritmo de base 10 (log10/2), para se obter uma distribuição mais uniforme dos dados quantitativos. Estes dados são representados por sequências de caracteres gráficos que indicam os seguintes valores:
Patamares de Frequência (log10/2):
Lemas: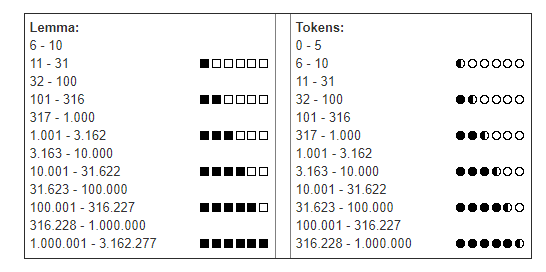
Indexação do Léxico por ordem alfabética:
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z
Indexação do Léxico por ordem de frequências decrescentes:
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12
Indexação do Léxico, com frequência numérica, por ordem alfabética:
lmcpc_alf.txt
Indexação do Léxico, com frequência numérica, por ordem de frequências decrescentes:
lmcpc_dec.txt
- Em todos os casos em que se refere a dimensão do corpus, palavra é sinónimo de ocorrência.
- Corpus aberto em contínuo desenvolvimento. À data da conclusão do Léxico (2000), o CRPC continha 150 milhões de palavras.
- Níveis de ensino a que se reportam os livros didácticos: 5º a 11º ano de escolaridade.
- Autorias colectivas foram contabilizadas como um só autor.
