CRPC - Reference Corpus of Contemporary Portuguese
version 3.0 2012
Online queries over the written subcorpus: platform CQPweb
Online queries over the spoken subcorpus: platform TEITOK
ISLRN: 151-982-545-991-0
The CRPC is a large electronic corpus of European Portuguese and other varieties (Brazil, Angola, Cape Verde, Guinea-Bissau, Mozambique, S. Tome and Principe, Goa, Macao and East-Timor). It contains 311,4 million words and covers several types of written texts (literary, newspaper, technical, etc.) and spoken texts (formal and informal).
The written subpart of the CRPC (309 M) can be searched online, and subparts of the corpus are available for download or for purchase on the ELDA catalogue.
Corpus citation
"data retrieved from the Reference Corpus of Contemporary Portuguese (CRPC) of the Centre of Linguistics of the University of Lisbon - CLUL (version 3.0 2012, using CQPWeb in the period [month/year])"
Corpus design
The CRPC contains 309,8M words of written texts and 1,6M words of spoken recordings and transcriptions.
It is called a ‘reference’ corpus in the sense that written texts are sampled before inclusion in the corpus.
- Text types
The CRPC covers several types of written texts: literary, newspaper, technical, scientific, didactic, leaflets, decisions of the supreme court of justice, parliament sessions, etc.
The CRPC includes a spoken subpart of both formal and informal speech. It covers different types of spoken interaction: monologues, dialogues, conversations, phone conversations, lectures, homilies, etc.
- Time
The CRPC contains texts from the second half of the 19th century up until 2006, but most of the texts have been produced after 1970.
- Portuguese varieties
The texts included in the CRPC are mainly of European Portuguese, but also from other national varieties of Portuguese in the world: Brazilian, African (Angola, Cape Verde, Guinea-Bissau, Mozambique and Sao Tome and Principe) and Asiatic Portuguese (Macao, Goa and East-Timor).
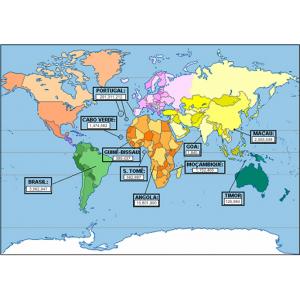
The map below signals all the varieties covered by the CRPC and gives information on the number of tokens for each one.
For information on the distribution of spoken and written texts per variety, see this table.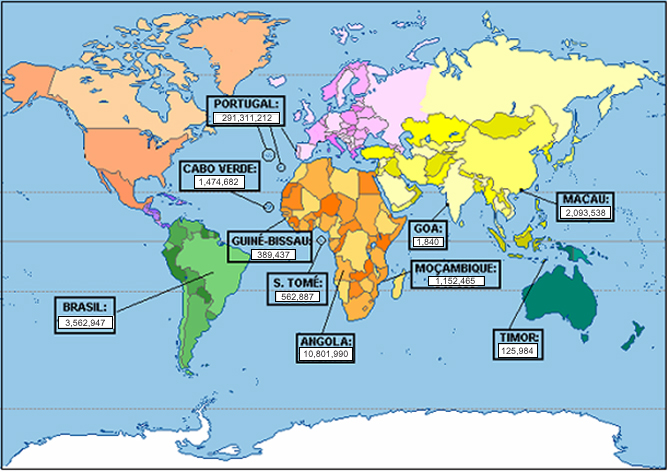
- Cleaning the corpus
The CRPC was cleaned using Ncleaner (Evert, 2008). With this approach, the texts are first cleared of all boilerplate material using simple rules. A language model is then used to free the text from irrelevant segments (adverts, spams). Our language model was built using 200 annotated documents picked randomly from the CRPC.
- Annotation
The texts are automatically tokenized using the LX tokenizer (Branco and Silva, 2004) which removes punctuation marks from words and detects sentence boundaries.
For part-of-speech tagging we trained a memory-based tagger (Daelemans et al, 1996) on a slightly adapted version of the written part of the CINTIL corpus. We use a tag set of 80 different tags.
For automatic lemmatization, we created a Portuguese version of the MBLEM lemmatizer (van den Bosch and Daelemans, 1999). MBLEM combines a dictionary lookup with machine learning to assign root forms to words. As dictionary we used the lemma list produced in the project DEP - Electronic Dictionary of Portuguese, coordinated at CLUL by Maria Elisa Macedo (the computational application was developed by João Miguel Casteleiro).
- Text-to-sound alignment of the spoken subcorpus
The spoken subcorpus has been text-to-sound aligned with the software EXMARaLDA (Schmidt, 2004). A previous subset (project C-ORAL-ROM) used the alignment software WinPitch.
Online queries
The written subpart of CRPC, composed of 309M tokens, is available to be searched online through CQPWeb.
To register, please send an email to: crpc.cqpweb at gmail.com
The spoken subpart of CRPC, text-to-sound aligned, is available to be searched online through TEITOK.
Availability
| Available subcorpora or derived resources | ||
| Project Name and Description |
Authorship | Available at |
|
Português Fundamental - published sample. |
CLUL |
aligned version: ELRA |
|
Português Falado - Variedades Geográficas e Sociais |
CLUL, Univ. de Toulouse-le-Mirail and Univ. de Provence Aix-Marseille |
4 Cd-Rom aligned version: ELRA |
| PAROLE Subcorpus A 3 million word subcorpus extracted from the PAROLE corpus, containing 250 000 morphosyntactic tagged words. |
CLUL and INESC | ELRA |
| LT Corpus A Literary Corpus that contains approximately 1,781,083 running words of 70 copyright-free classics of European and Brazilian literature (61 Portugal and 9 from Brazil) published before 1940. Freely available for research at ELRA. |
CLUL | ELRA |
|
PTPARL Corpus |
CLUL | ELRA |
| LMCPC A 26 980 lemma and 140 976 form lexicon with morphological and quantitative information. |
CLUL, INESC and Editorial Verbo |
aqui |
| PAROLE LEXICON A 20 000 morphosyntactic tagged unit lexicon with syntactic description. |
CLUL, INESC and Editorial Verbo |
ELRA |
| SIMPLE A 300 unit PAROLE sub-lexicon with semantic description. |
CLUL, Portuguese and European partnership | |
History
The CRPC project started in 1988, at CLUL. The team had previously been involved in the compilation of the spoken corpus Português Fundamental and the new project was a natural follow-up to cover both spoken and written texts.
The corpus was initially planned to be balanced but later evolved into a monitor corpus. A subcorpus of 11 million words was made available for the search of concordances and frequencies and has been replaced by the CQPWeb platform, which enables a large set of search options.
Acknowledgements
Funding
- Fundação Calouste Gulbenkian
- Junta Nacional de Investigação Científica e Tecnológica (JNICT) - Programme Estímulo em Ciências sociais e Humanas
- Fundação para a Ciência e Tecnologia (FCT) - Fundos Programáticos
- Instituto Camões
- União Latina
- Caixa Geral de Depósitos
- European Commission: LE-PAROLE and C-ORAL-ROM projects.
Data suppliers
- Academia das Ciências de Lisboa
- Agência Lusa
- Assembleia da República
- Caixa Geral de Depósitos
- Centro de Informática do Ministério da Justiça
- Coimbra Editora
- DECO
- Editora Colibri
- Editora Nova Fronteira - Brasil
- Editorial Verbo
- Estação de Rádio TSF
- Fundação Calouste Gulbenkian - Serviço de Bibliotecas e Apoio à Leitura
- Instituto do Consumidor
- Sociedade Bíblica Portugal
- Portuguese newspapers: A Bola, A Capital, Diário de Notícias, Diário Económico, Expresso, Jornal de Notícias, Diário do Minho, O Independente, Público
- Cape Verdean newspapers: A Semana, Correio Quinze, Novo Jornal
- Procuradoria-Geral da República
- Corpus do Português Contemporâneo (Universidade Estadual Paulista - UNESP
- NURC-BR project (São Paulo e Rio de Janeiro)
- PEUL project (Rio de Janeiro)
- Periodical: Grande Reportagem, Ingenium, Máxima, ProTeste, Visão; Selecções do Reader's Digest
The CQPweb interface was designed and developed by Andrew Hardie. We would like to thank Andrew for helping us adapting the interface for Portuguese. We thank the NLX Group (Natural Language and Speech) at the Faculty of Sciences of the University of Lisbon, coordinated by António Branco, for granting us access to their LX-Tokenizer.
We would also like to thank Thomas Schmidt for adapting the EXMARaLDA software to previous formats used at CLUL.
Contact
If you have any question or suggestion concerning CRPC, please contact us at amaliamendes@letras.ulisboa.pt.
Research
The CRPC has been used in many MA and Ph.D studies carried out in Portugal and abroad, and in research projects such as the Dicionário da Língua Portuguesa Contemporânea of the Academia das Ciências de Lisboa, which used the CRPC as a source of quotations. It was also used in the following projects at CLUL:
- Comprehensive Grammar of the Portuguese Language
- Language Resources for Portuguese: a corpus and tools for query and analysis
- REDIP - International Portuguese Broadcasting Network: radio, television and press
- Multifunctional Computacional Lexicon of Contemporary Portuguese
- Spoken Portuguese - Geographical and Social Varieties
- SIMPLE - Semantic Information for Multifunctional Plurilingual Lexicon
- LE-PAROLE
- ELAN - European Language Activity Network
- DCP - The Combinatory Dictionary of Portuguese
- AUDIOLING-LP - Portuguese Language: sound and pronunciation application for the Portuguese teaching
- Study of the preposition DE use and meaning in nominal contexts
- Portuguese Language: computer-aided teaching
- C-ORAL-ROM - Integrated Reference Corpora for Spoken Romance Languages
- ENABLER - European National Activities for Basic Language Resources
- VARPORT - Análise Contrastiva de Variedades do Português
References
van den Bosch, Antal and Walter Daelemans (1999) Memory-based morphological analysis. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics (ACL '99). Association for Computational Linguistics, Stroudsburg, PA, USA, 285-292.
Branco, António e João Silva (2004) Evaluating Solutions for the Rapid Development of State-of-the-Art POS Taggers for Portuguese. In Maria Teresa Lino, Maria Francisca Xavier, Fátima Ferreira, Rute Costa and Raquel Silva (orgs.), Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC2004), Paris, ELRA, ISBN 2-9517408-1-6, pp.507-510.
Evert, Stefan (2008) A lightweight and efficient tool for cleaning web pages. In 6th International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco.
MBT: A Memory-Based Part of Speech Tagger-Generator. Walter Daelemans, Jakub Zavrel, Peter Berck and Steven Gillis. in: E. Ejerhed and I. Dagan (eds.) Proceedings of the Fourth Workshop on Very Large Corpora, Copenhagen, Denmark, 14-27, 1996.
Schmidt, Thomas (2004) Transcribing and annotating spoken language with EXMARaLDA. In: Proceedings of the LREC-Workshop on XML based richly annotated corpora, Lisbon 2004, Paris: ELRA.


João Malaca Casteleiro
Maria Lúcia Garcia Marques
José Bettencourt Gonçalves
Raquel Amaro
Florbela Barreto
João Miguel Casteleiro
Tiago Sá
Sandra Antunes
Rita Veloso
Iris Hendrickx
