CRPC - Corpus de Referência do Português Contemporâneo
version 3.0 2012
Pesquisa online do subcorpus escrito: platforma CQPweb
Pesquisa online do subcorpus oral: plataforma TEITOK
ISLRN: 151-982-545-991-0
O CRPC é um vasto corpus electrónico da variedade europeia do Português e de outras variedades (Brasil, Angola, Cabo Verde, Guiné-Bissau, Moçambique, São Tomé e Príncipe, Goa, Macau, Timor-Leste). Contendo 311,4 milhões de palavras, este corpus abrange diferentes tipos de textos escritos (literário, jornalístico, técnico, etc.) e de registos orais (formal e informal).
O subcorpus escrito do CRPC (309 milhões de palavras) pode ser pesquisado online e subpartes do corpus encontram-se disponíveis no catálogo ELRA.
Citação do corpus
"dados extraídos do Corpus de Referência do Português Contemporâneo (CRPC) do Centro de Linguística da Universidade de Lisboa – CLUL (versão 3.0 2012, através da plataforma CQPWeb no período [mês/ano])”
Composição
O CRPC é composto por 309,8 milhões de palavras provenientes de textos escritos e 1,6 milhões de palavras provenientes de transcrições de gravações de registos orais.
É considerado um corpus de referência na medida em que os textos escritos foram sujeitos a um processo de amostragem previamente à sua inclusão no corpus.
- Tipos de texto
O CRPC abrange diversos tipos de textos escritos: literário, jornalístico, técnico, científico, didáctico, folhetos, decisões do Supremo Tribunal de Justiça, sessões parlamentares, etc.
O CRPC é também constituído por um subcorpus oral que inclui discurso formal e informal. Este subcorpus cobre diferentes tipos de interacção: monólogos, diálogos, conversas, telefonemas, leituras, homilias, etc.
- Datação
O CRPC contém textos da segunda metade do século XIX até 2006, embora a maioria dos textos seja posterior ao ano de 1970.
- Variedades do Português
Os textos incluídos no CRPC pertencem maioritariamente à variedade europeia do Português, mas encontram-se também representadas no corpus outras variedades nacionais, como o Português do Brasil, de África (Angola, Cabo Verde, Guiné-Bissau, Moçambique e São Tomé e Príncipe) e da Ásia (Macau, Goa e Timor-Leste).
O mapa que abaixo se apresenta assinala todas as variedades abrangidas pelo CRPC. Nele pode encontrar-se informação acerca do número de palavras existente para cada uma das variedades.
Para obter informações sobre a distribuição de textos escritos e orais por variedade, consulte-se esta tabela.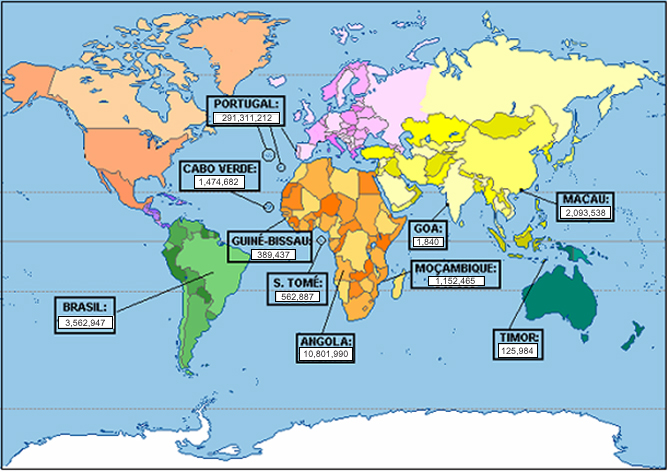
Anotação
- Preparação do corpus
O CRPC foi limpo com a ferramenta Ncleaner (Evert, 2008), adaptada com recurso a 200 documentos anotados, seleccionados aleatoriamente do CRPC. Foi assim possível limpar os textos de informação repetida ou não relevante (publicidade, spam).
- Anotação
Os textos foram automaticamente tokenizados com o tokenizador LX (Branco & Silva, 2004), que retira sinais de pontuação e detecta fronteiras de frase.
Para a etiquetagem morfossintáctica, foi treinado o etiquetador desenvolvido por Daelemans et al. (1996) com uma versão ligeiramente adaptada da parte escrita do corpus CINTIL. O sistema de anotação usado contém um conjunto de 80 etiquetas.
Para a lematização automática, foi criada uma versão portuguesa do lematizador MBLEM (van den Bosch & Daelemans, 1999). O MBLEM atribui lemas a cada forma do corpus, aliando a pesquisa em dicionários com a aprendizagem automática. Como dicionário, foi usada a lista de lemas construída no âmbito do projecto DEP – Dicionário Electrónico do Português, coordenado no CLUL por Maria Elisa Macedo (tendo a aplicação informática sido desenvolvida por João Miguel Casteleiro).
- Alinhamento das transcrições do subcorpus oral
O alinhamento de transcrições ortográficas com o sinal acústico foi realizado com o programa EXMARaLDA (Schmidt, 2004). No âmbito do projecto C-ORAL-ROM, foi ainda utilizado o programa WinPitch.
Pesquisas online
O subcorpus escrito do CRPC, composto por 309 milhões de tokens, encontra-se disponível para pesquisas online através da interface CQPWeb.
O registo, obrigatório e gratuito, é feito por pedido endereçado a: crpc.cqpweb at gmail.com
O subcorpus oral do CRPC, com alinhamento texto-som, pode ser pesquisado na plataforma TEITOK.
Disponibilidade
| Subcorpora disponíveis ou recursos deles derivados | ||
| Nome do Projecto e Descrição |
Autoria | Disponível em |
|
Português Fundamental - amostra publicada. Versão transcrita e alinhada no formato EXMARaLDA disponível no catálogo ELRA (gratuita para investigação) |
CLUL |
versão alinhada: catálogo ELRA |
|
Português Falado - Variedades Geográficas e Sociais Versão transcrita e alinhada no formato EXMARaLDA disponível no catálogo ELRA (gratuita para investigação) |
CLUL, Univ. de Toulouse-le-Mirail e Univ. de Provence Aix-Marseille |
4 Cd-Rom versão alinhada: catálogo ELRA |
| Subcorpus PAROLE subcorpus composto por 3 milhões de palavras e extraído do corpus PAROLE; contém 250 000 palavras etiquetadas com informação morfossintáctica. |
CLUL e INESC | Catálogo ELRA |
|
LT Corpus Corpus de obras literárias livres de direitos de autor (61 obras portuguesas e 9 obras do Brasil), publicadas antes de 1940. Disponível no catálogo ELRA (gratuito para investigação) |
CLUL | Catálogo ELRA |
|
PTPARL Corpus Corpus com 1,076 transcrições dos Diários da Assembleia da República, com 1,000,441 tokens e anotação PoS e NP chunks. Disponível no catálogo ELRA (gratuito para investigação) |
CLUL | Catálogo ELRA |
| LMCPC léxico composto por 26 980 lemas e 140 976 formas com informação morfológica e quantitativa. |
CLUL, INESC e Editorial Verbo |
aqui |
|
PAROLE LEXICON |
CLUL, INESC e Editorial Verbo |
Catálogo ELRA |
| SIMPLE subléxico do PAROLE com 300 unidades acompanhadas de descrição semântica. |
CLUL, parceria Portuguesa e Europeia | |
História
O projecto CRPC teve início em 1988, no CLUL. A equipa responsável por este projecto havia estado também envolvida na compilação do corpus oral Português Fundamental. Assim, o novo projecto surgiu no seguimento daquele com o objectivo de abranger textos escritos e orais. O corpus foi inicialmente pensado para ser um corpus equilibrado, mas acabou por se tornar um corpus "monitor”. Um subcorpus de 11 milhões de palavras foi inicialmente disponibilizado online para pesquisa de concordâncias e frequências através da ferramenta Concor. A totalidade do CRPC escrito está agora disponível na plataforma CQPWeb, que permite um vasto leque de opções de pesquisa (ver informação abaixo).
Agradecimentos
Financiamento
- Fundação Calouste Gulbenkian
- Junta Nacional de Investigação Científica e Tecnológica (JNICT) - Programa Estímulo em Ciências sociais e Humanas
- Fundação para a Ciência e Tecnologia (FCT) - Fundos Programáticos
- Instituto Camões
- União Latina
- Caixa Geral de Depósitos
- Comissão Europeia: projectos LE-PAROLE e C-ORAL-ROM.
Entidades que disponibilizaram textos
- Academia das Ciências de Lisboa
- Agência Lusa
- Assembleia da República
- Caixa Geral de Depósitos
- Centro de Informática do Ministério da Justiça
- Coimbra Editora
- DECO
- Editora Colibri
- Editora Nova Fronteira - Brasil
- Editorial Verbo
- Estação de Rádio TSF
- Fundação Calouste Gulbenkian - Serviço de Bibliotecas e Apoio à Leitura
- Instituto do Consumidor
- Sociedade Bíblica Portugal
- Jornais portugueses: A Bola, A Capital, Diário de Notícias, Diário Económico, Expresso, Jornal de Notícias, Diário do Minho, O Independente, Público
- Jornais cabo-verdianos: A Semana, Correio Quinze, Novo Jornal
- Procuradoria-Geral da República
- Corpus do Português Contemporâneo (Universidade Estadual Paulista - UNESP
- Projecto NURC-BR (São Paulo e Rio de Janeiro)
- Projecto PEUL (Rio de Janeiro)
- Periódicos: Grande Reportagem, Ingenium, Máxima, ProTeste, Visão; Selecções do Reader's Digest
A interface CQPweb foi projectada e desenvolvida por Andrew Hardie. Gostaríamos de lhe agradecer por nos ajudar a adaptar a interface para o Português. Agradecemos igualmente ao Grupo NLX (Natural Language and Speech) da Faculdade de Ciências da Universidade de Lisboa, coordenado por António Branco, por nos dar acesso ao programa tokenizador LX.
Agradecemos também a Thomas Schmidt por adaptar o software EXMARaLDA a formatos anteriormente usados no CLUL.
Contacto
Para qualquer questão ou sugestão relativamente ao CRPC, por favor contacte-nos através do endereço electrónico amaliamendes@letras.ulisboa.pt.
Investigação
O CRPC foi já usado em vários trabalhos de mestrado e doutoramento conduzidos em Portugal e no estrangeiro, bem como em trabalhos de investigação como o Dicionário da Língua Portuguesa Contemporânea da Academia das Ciências de Lisboa, em que se recorreu ao CRPC como fonte de abonações. O CRPC foi ainda usado nos seguintes projectos do CLUL:
- Gramática do Português
- Recursos Linguísticos para o Português: um corpus e instrumentos para a sua consulta e análise
- REDIP - Rede de Difusão Internacional do Português: rádio, televisão e imprensa
- Léxico Multifuncional Computorizado do Português Contemporâneo
- Português Falado - Variedades Geográficas e Sociais - CD-Rom
- SIMPLE – Semantic Information for Multifunctional Plurilingual Lexicon
- LE-PAROLE
- ELAN – European Language Activity Network
- DCP - Dicionário de Combinatórias do Português
- AUDIOLING-LP - Língua Portuguesa: som e pronúncia
- Estudo do Uso e do Significado da Preposição DE em contextos nominais SN DE SN
- Língua Portuguesa: Ensino Assistido por Computador
- C-ORAL-ROM – Integrated Reference Corpora for Spoken Romance Languages
- ENABLER - European National Activities for Basic Language Resources
- VARPORT - Análise Contrastiva de Variedades do Português
Referências bibliográficas
van den Bosch, Antal and Walter Daelemans (1999) Memory-based morphological analysis. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics (ACL '99). Association for Computational Linguistics, Stroudsburg, PA, USA, 285-292.
Branco, António e João Silva (2004) Evaluating Solutions for the Rapid Development of State-of-the-Art POS Taggers for Portuguese. In Maria Teresa Lino, Maria Francisca Xavier, Fátima Ferreira, Rute Costa and Raquel Silva (orgs.), Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC2004), Paris, ELRA, ISBN 2-9517408-1-6, pp.507-510.
Evert, Stefan (2008) A lightweight and efficient tool for cleaning web pages. In 6th International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco.
MBT: A Memory-Based Part of Speech Tagger-Generator. Walter Daelemans, Jakub Zavrel, Peter Berck and Steven Gillis. in: E. Ejerhed and I. Dagan (eds.) Proceedings of the Fourth Workshop on Very Large Corpora, Copenhagen, Denmark, 14-27, 1996.
Schmidt, Thomas (2004) Transcribing and annotating spoken language with EXMARaLDA. In: Proceedings of the LREC-Workshop on XML based richly annotated corpora, Lisbon 2004, Paris: ELRA.


João Malaca Casteleiro
Maria Lúcia Garcia Marques
José Bettencourt Gonçalves
Raquel Amaro
Florbela Barreto
João Miguel Casteleiro
Tiago Sá
Sandra Antunes
Rita Veloso
