DUPLEX - Doubles and Expletives in European Portuguese Dialect Syntax
The project DUPLEX aimed at promoting the study of European Portuguese dialect syntax by means of a twofold approach:
(i) implementation of an online linguistic resource feeding the empirical demands of dialect syntax;
(ii) theoretically-oriented investigation of concerted topics in Portuguese dialect syntax, focused on doubling and expletive constructions within a Principles and Parameters perspective.
This project contributed to the research developed within the project Syntax-oriented Corpus of Portuguese Dialects (CORDIAL-SIN): firstly, as an enhancement of the compiled dialectal corpus (CORDIAL-SIN 2007, 2010), which is now provided with sentence-based annotation for syntactic structure, thus becoming a more efficient resource for the purpose of studying syntax; secondly, as an in-depth study of a selection of topics in the domain of Portuguese dialect syntax.
The research developed within DUPLEX shapes the team's collaboration at international fora on dialect syntax, namely the European network of (dialect) syntacticians established by the Edisyn project (Meertens Institute, Amsterdam) and the Wedisyn network (Dialect Syntax in Westmost Europe).
Project description:
DUPLEX is a three-year project (2008-2010) aimed at promoting the study of European Portuguese dialect syntax by means of a twofold approach: (i) implementation of an online linguistic resource feeding the empirical demands of dialect syntax; (ii) theoretically-oriented investigation of concerted topics in Portuguese dialect syntax, focused on doubling and expletive constructions within a Principles and Parameters perspective.
The project extends the research developed within the projects CORDIAL-SIN (PRAXIS XXI/P/PLP/113046/1998), CORDIAL-SIN-2 (POSI/1999/PLP/33275) and Dialectal Syntax (POCTI/LIN/46980/2002): firstly, as an enhancement of the compiled dialectal corpus (CORDIAL‑SIN), which is now provided with sentence-based annotation for syntactic structure, thus becoming a more efficient resource for the purpose of studying syntax; secondly, as an in-depth study of a selection of topics in the domain of Portuguese dialect syntax.
The syntactic annotation of CORDIAL-SIN
The compilation of the Syntax-Oriented Corpus of Portuguese Dialects (CORDIAL-SIN) was achieved in 2007. This corpus is based on a geographically representative body of selected excerpts of spontaneous and semi-directed speech, drawn from the rich recorded speech collection gathered by the ATLAS research team of the group Dialectology and Diachrony at CLUL. Since 2007, the corpus (600,000 words) is available online for download, by geographical location and under three different formats: verbatim transcripts, normalized transcripts, part-of-speech tagged files. One of the aims of the project DUPLEX is to make CORDIAL-SIN available as a parsed corpus.
The syntactic annotation is implemented over CORDIAL-SIN part-of-speech tagged texts. The annotation system, in the Penn Treebank format, has been set up in close collaboration with other research groups engaged in the building up of syntactically annotated corpora, namely the Tycho Brahe Corpus and the Penn Parsed Corpora of Historical English. The annotation results in a tree representation in the form of labeled brackets, marking constituent boundaries, phrase and clause dependencies, sentence types, grammatical relations, null categories and some transformational relations (see CORDIAL-SIN Syntactic Annotation Manual). The CORDIAL-SIN annotation system also counts with a set of labels/annotation conventions for pragmatic units. The syntactically annotated corpus allows automatic searches for syntactic structure through the search program CorpusSearch2, written by Beth Randall (open source software, downloadable from Sourceforge), which is compatible with syntactic annotations in the Penn Treebank format.
CORDIAL-SIN is searchable online through the Edisyn Search Engine
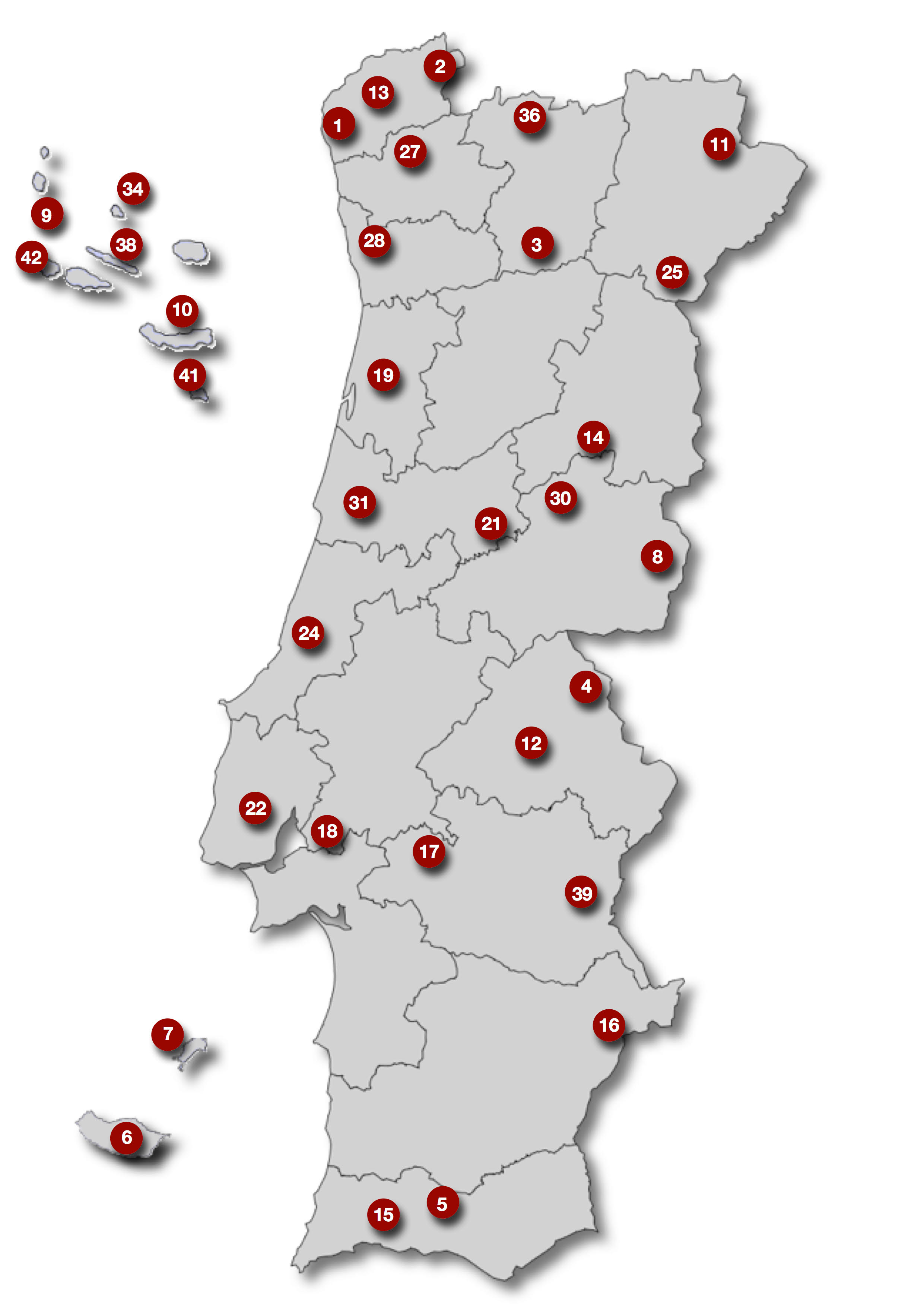
The syntactic annotation of CORDIAL-SIN is released in a phased manner. The present release provides access to the annotated texts of the thirty-three locations marked on the map below.
Download zip-file – annotated data in labeled bracketing format.
The annotated texts are automatically searchable with CorpusSearch, a search engine for parsed corpora developed by Beth Randall (open source software, downloadable from Sourceforge).
Documentation: CORDIAL-SIN Syntactic Annotation System Manual
 |
|

CORDIAL-SIN by Centro de Linguística da Universidade de Lisboa is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.








